为什么要用vector,如果日志量小elk或者loki就够了,但是如果每天的日志量达到TB级别,在节省开支的情况下可以考虑这个架构了
首先介绍官网:
和其他工具对比
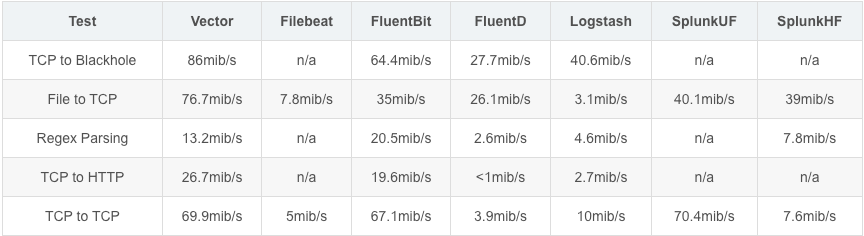
可靠性对比

功能性对比

环境描述:
本次演示以收集nginx日志为例,通过filebeat采集到kafka集群,然后通过vector消费kafka消息再保存到es,通过kibana展示es数据,其中es和kafka搭建环节省略了,主要看filebeat和vector的配置
软件版本:
filebeat:7.5
vector:0.41.1
kafka:2.13-3.6.1
官网下载地址:
解压后vector保存路径
[root@demo-226 vector]# pwd
/data/vector
[root@demo-226 vector]# ls
bin config data etc licenses logs
[root@demo-226 vector]#
配置系统服务
[Unit]
Description="Vector - An observability pipelines tool"
Documentation=https://vector.dev/
Wants=network-online.target
After=network-online.target
[Service]
LimitNOFILE=1000000
#LimitCORE=infinity
LimitSTACK=10485760
User=root
# 这里-t是开启的线程数量,根据服务器实际配置设置
# --config-dir是指定配置文件的目录,前提是目录中所有配置文件都要正确
# 也可以指定单个配置文件 -c /data/vector/config/vector.yaml
ExecStart=/data/vector/bin/vector -t 4 --config-dir=/data/vector/config/
Restart=always
AmbientCapabilities=CAP_NET_BIND_SERVICE
[Install]
WantedBy=multi-user.target
手动前台启动方式
[root@demo-226 vector]# /data/vector/bin/vector -c /data/vector/config/vector.yaml
vector的配置文件大致分3类,分别是输入源配置(sources),数据处理配置(transforms),目标输出配置(sinks)
以下面这段配置为例,这是一段yaml文件配置,所以格式很重要
# 数据在本地缓存目录
data_dir"/data/vector/data"
# 数据源,vector支持的数据源有多种,具体可以参考官网
sources
# 本数据源的名称,后面会用到,可以配置多个数据源,名称可以自定义
kafka_source
# 数据源的类型,这个需要在官网查询支持的类型名称,不能写错,以kafka为例
typekafka
# kafka集群的地址,多个地址之间用逗号隔开
bootstrap_servers172.20.20.2279092,172.20.20.2289092,172.20.20.2299092
# kafka的消费组名称
group_idkafka_group
# 消费偏移
auto_offset_reset"latest"
# 消费的topic
topics
nginx
demo
# 数据处理阶段,可以过滤,增加删除字段等操作,这个环节可以不要
transforms
# 名称自定义
my_transform
# 使用的处理模块,支持的模块需要参考官网
typeremap
# 数据输入源名称,比如上面配置的kafka源名称
inputs
kafka_source
# 数据处理,这是使用的vrl语法
source
# 使用json解析,将message字段重新赋值给根节点,message的值就是kafka中读取的原始值
. = parse_json!(.message)
# 获取当前utc时间的时间戳
index_time = parse_timestamp!(now(), "unix")
# 对utc时间戳增加4小时
index_time = from_unix_timestamp!(to_int(index_time) + 14400)
# 将增加4小时后时间格式化
index_time = format_timestamp!(index_time, "%Y-%m-%d")
# 对索引名字后面加上格式化后的时间
.indexname = join!([.service, index_time], separator: "-")
# del是删除字段
del(.@metadata)
del(._score)
del(._type)
del(.agent.type)
del(.agent.version)
del(.ecs)
# 新增字段
.@timestamp = now()
# 重命名字段
.age = del(.value)
# 数据输出,当前配置是输出到终端,一般用来调试配置
sinks
# 名称自定义
my_sink_id
# 当前类型是终端,具体支持的类型可以参考官网
typeconsole
# 使用输入的数据源名称,可以使用多个数据源,也可以使用数据处理阶段的名称
inputs
my_transform
encoding
codec"json"
sinks
my_sink_id
typeelasticsearch
inputs
my_transform
api_versionauto
# 压缩方式
compressiongzip
doc_type_doc
endpoints
http://172.20.20.226:9200
# 用户认证
auth
strategybasic
user"elastic"
password"Aa123456"
id_keyid
modebulk
# 索引名称,可以使用字段值作为索引名称
bulk
index"{{ .indexname }}-%Y-%m-%d"
# 这个值可以通过这种方式查询 curl -X GET "http://127.0.0.1:9200/_ingest/pipeline"
pipeline"xpack_monitoring_7"
2.2、filebeat配置
filebeat.inputs
typelog
enabledtrue
paths
/data/openresty/nginx/logs/access.log
# 标签名称
tags"access"
# 添加自定义字段
fields
service"nginx-226"
# 是否把自定义字段添加到根路径
fields_under_roottrue
output.kafka
hosts"172.20.20.227:9092""172.20.20.228:9092""172.20.20.229:9092"
topic"nginx"
partition.round_robin
randomizetrue
leader_onlyfalse
required_acks1
# 压缩方式
compressiongzip
# 压缩级别,1-9可选,数越大压缩率越高,越消耗性能,
compression_level9
codec.format"json"
codec.json.add_crfalse
max_message_bytes1000000