Prometheus除了监控外还有告警功能,但是需要使用到它的告警模块,其实grafana也可以实现告警功能,但是我们在grafana中使用面板是有变量的,目前grafana对使用变量的面板不支持告警功能,期待它的后续版本的支持。
Prometheus的告警模块也可以在官网下载到,名字叫:alertmanager,自行下载并上传到服务端,可以和Prometheus放在同一台服务器
1、安装alertmanager
[root@server1 soft]# ls
alertmanager-0.21.0.linux-amd64.tar.gz
[root@server1 soft]# tar -zxvf alertmanager-0.21.0.linux-amd64.tar.gz
[root@server1 soft]# ls
alertmanager-0.21.0.linux-amd64 alertmanager-0.21.0.linux-amd64.tar.gz
[root@server1 soft]# mv alertmanager-0.21.0.linux-amd64 /usr/local/alertmanager/
按照上面的操作将alermanager放在/usr/local/下并改名为alermanager,简单的对alertmanager配置:
[root@server1 alertmanager]# cat alertmanager.yml
global:
#告警触发后的解除间隔
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 20s
group_interval: 45s
#重复警告的发送间隔
repeat_interval: 10m
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- send_resolved: false
url: 'https://www.xxx.com/alert.php'
inhibit_rules:
- source_match:
alertname: hostcpu
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
[root@server1 alertmanager]#
上面是本次演示简单的配置一下,告警通知方式支持很多种,有邮件、钉钉、webhook等等,本次演示使用webhook,这个webhook接口是我自己临时写的,因为需要对接我们自己工作使用的通讯工具,而alert目前还不支持我们的这个通讯工具,当有告警时它会向这个地址发送一个json格式的数据流,只需要将它的json数据解析出来并发送到指定的通讯接口就可以了。
global是全局配置
route是通知路由,从左向右匹配
receivers是接收告警的方式
inhibit_rules是告警抑制,意思是相同的告警避免重复发送
这是告警的通知方式以及间隔时间和告警抑制,至于其他的参数配置可以参考官方文档或者百度一下,篇幅限制这里不再过多介绍了,下面就需要配置告警规则了
启动alertmanager
[root@server1 ~]# /usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml
[root@server1 ~]# ps -ef | grep alert
root 12367 1 0 15:07 pts/0 00:00:00 /usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml
root 12385 12017 0 15:07 pts/0 00:00:00 grep --color=auto alert
[root@server1 ~]# netstat -tunlap| grep alert
tcp6 0 0 :::9093 :::* LISTEN 12367/alertmanager
tcp6 0 0 :::9094 :::* LISTEN 12367/alertmanager
udp6 0 0 :::9094 :::* 12367/alertmanager
alert默认监听的是9093端口,到此alert安装完成
2、配置告警规则
我们回到prometheus的目录:/usr/local/prometheus/,修改主配置文件,只需要添加一行代码:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 1m # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- /usr/local/prometheus/rules/*.rules
需要添加的是上文中第16行,意为加载rules目录下的所有.rules文件,后续添加告警规则只需要在该目录下添加配置文件就好了
evaluation_interval: 1m 表示检测告警的间隔时间
127.0.0.1:9093表示我们刚才安装的alermanager的监听地址,因为是装在本机,所以这里填写本地地址。
其他的不清楚的可以先保持默认即可,下面来添加一个告警配置文件:
首先需要在/usr/local/prometheus/目录下创建rules目录,然后在rules目录下新建.rules结尾的文件
[root@server1 prometheus]# pwd
/usr/local/prometheus
[root@server1 prometheus]# mkdir rules
[root@server1 prometheus]# ls
console_libraries consoles data LICENSE NOTICE prometheus prometheus.yml promtool rules
[root@server1 prometheus]# cd rules/
[root@server1 rules]# touch test.rules
[root@server1 rules]# ls
test.rules
[root@server1 rules]#
test.rules文件的内容如下:
[root@server1 rules]# cat test.rules
groups:
- name: test1
rules:
- alert: hostcpu
expr: ceil((1- ((sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by(instance)) / (sum(increase(node_cpu_seconds_total[1m])) by(instance))))*100) > 80
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} CPU usgae high"
description: "{{ $labels.instance }} CPU 使用率超过 80% (当前使用率为: {{ $value }}%)"
- alert: hostmem
expr: ceil((1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes))*100) >80
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} MEM usgae high"
description: "{{ $labels.instance }} 内存使用率超过 80% (当前使用率为: {{ $value }}%)"
[root@server1 rules]#
主要的几个参数说明一下:
expr:监控的项目,语法是promql,具体写法可以参考grafana面板的监控项目中的配置,我这里也是参照它的写法,不用花心思去研究它的具体需要怎么写,抄就完了。
这里说一下ceil()这个函数,它的作用是对数字做四舍五入并取整处理
for:当告警触发后持续多久再发出告警
severity:严重级别的定义,当需要对告警做抑制配置的时候会用到
description:是告警触发后发送通知的内容
配置完成后需要重新加载一下prometheus配置让这个告警规则生效,这里我写了一个小脚本来实现:
#!/bin/bash
pid=$(lsof -i|grep prometheu|tail -n1|awk '{print $2}')
if [[ $pid != "" ]];then
echo $pid
kill -HUP $pid
else
echo "start"
/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --storage.tsdb.path=/usr/local/prometheus/data 2>&1 &
fi
不用脚本也可以,脚本的大意为:如果prometheus在运行就热加载一次配置文件,如果没有运行就启动它。
3、告警测试
告警规则配置完成可以通过prometheus的web管理界面查看:
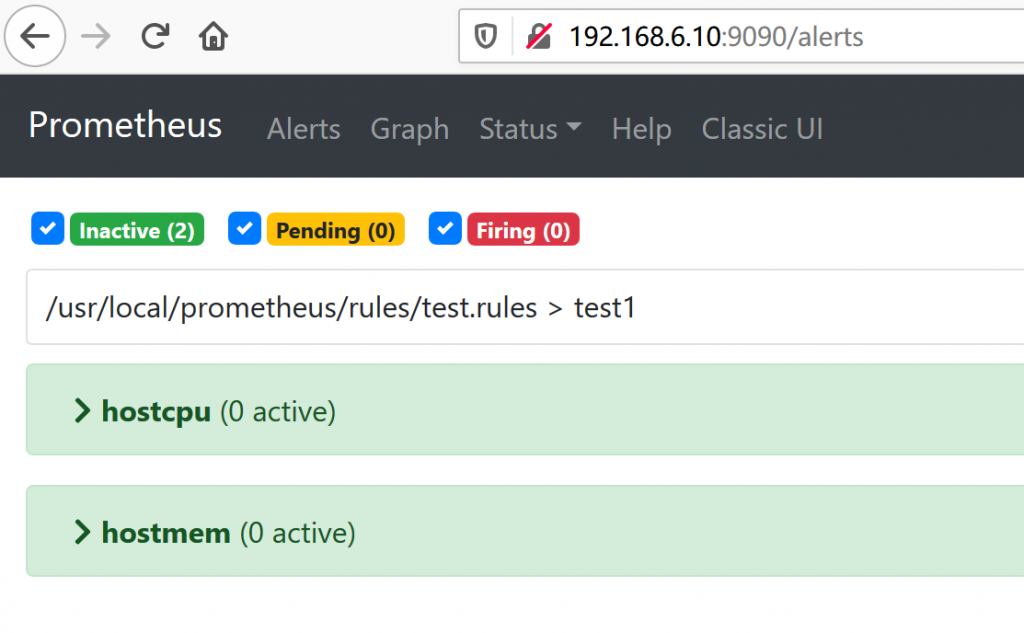
可以看到我们刚才添加的两个监控项目,下面就来对cpu的监控项目做一下测试看是否能触发监控并发送告警,通过这条命令将监控客户端的机器cpu负载提高到监控目标值之上
[root@nginx ~]# cat /dev/urandom | gzip -9 | gzip -d | gzip -9 | gzip -d >/dev/null
可以通过top看到cpu负载已经超过了80%

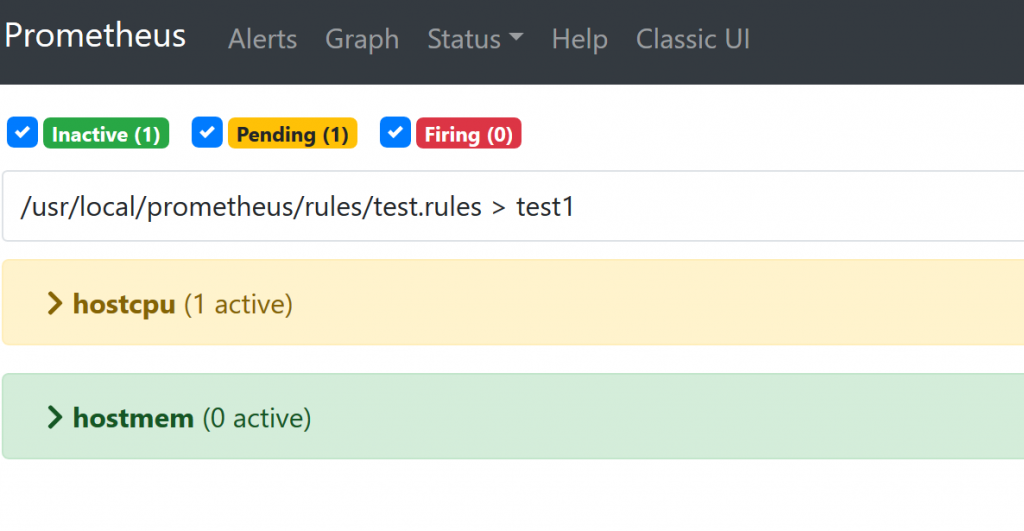
通过web界面可以看到已经触发了告警阈值,如果再坚持1分钟就会触发告警
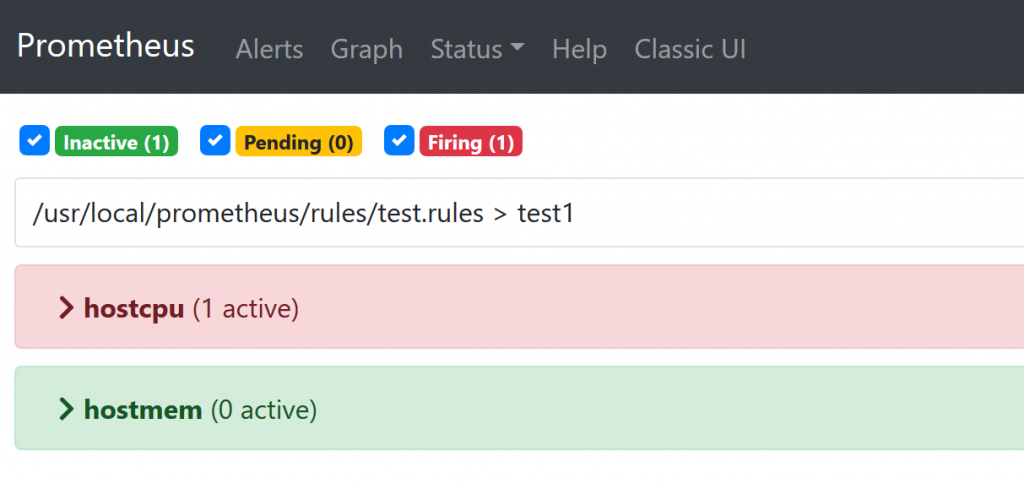
已经触发告警,如果告警通知接口没问题就会收到它的告警内容。